3.26 校内模拟赛游记
完完全全 PJ 难度的比赛,居然给我玩炸了.......
大概就是 分钟前两道,T3 是有些恶心的大模拟,写了 ,结果还挂在了俩傻傻的问题上。 T4 一道巧妙的题,但模拟样例时想歪了,最后没有做出来。所以赶紧写游记,下次不能再犯这样的错误了。
只讲 T3 & T4.
T3
考虑如何判断相似的情况,暴力的做法是要判断四次旋转和一个镜像共八种,但当然不会去真的旋转,不同的方向只是角度的不同,循环的时候变一下顺序就可以了。
暴力判断会超时,我没有想到题解中的神奇定理,于是大力哈希了,将每个块抠出来,每行分开拼成一个二进制数。但这样是错的,如下面这种情况。
11
11
二进制是 , 和 1111 的哈希值是一样的。为了解决这个问题,随便在换行的时候做点什么即可,如果您担心其它的重复,只要上多次哈希就好了,赛场上我写了三哈希,如果不是错误的哈希做法,这样重复的概率大概是很小的。
染色的时候我本来想着反正也染了就不用来判重复了吧,但遗憾的是,不行。
如这样子的数据。
1111
1111
1111
1111
...
1111
1111
就会被大量地重复塞入,因为 塞入了 , 但先走到了 , 然后再次塞入了 ,这样会有大量的重复,最终超时和超空间。
代码总长度达 行。但模块化做的非常的好 自卖自夸 思路特别的清晰。
大概理一下思路(来自赛场草稿):
- 遍历
- 抠出图形
- bfs 找出联通的和起始块的相对位置
- 修正坐标,让最小的 横/纵 都是
- 哈希
- 包括镜像的共八个方向处理
- 三个模数都跑一遍
- 对 个哈希值排序,以处理不同方向读到顺序不同的情况
- 比较
- 如果前面没有就新开一个
- 染色
因为最多星座不超过 所以时间复杂度是对的。
主程序(没什么东西,就是遍历一遍,如果是 , 就执行上面的操作):
int main() {
scanf("%d%d", &m, &n);
for(int i = 1; i <= n; i++)
scanf("%s", map[i]+1);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
if(map[i][j] == '1') doit(i, j);
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) putchar(map[i][j]);
putchar('\n');
}
return 0;
}
然后是 doit 函数, 各个函数都是字面意思,就是把上面所说的给组织了一下。
void doit(int i, int j) {
int x = 0, y = 0;
getClu(i, j, x, y);
twt a = hashClu(x, y);
int pos = findClu(a);
if(pos == -1) {
clusters.push_back(a);
pos = ++totC;
}
Color(i, j, pos + 'a' - 1);
initClu(x, y);
}
再看 getClu,同样没有什么东西
void getClu(int sx, int sy, int &n, int &m) {
bfs(sx, sy);
revize(n, m);
}
相信 bfs 很容易实现,来看 revize, 修正也很简单,就是找到最小的然后都加上它和一的差。
void revize(int &n, int &m) {
n = 0, m = 0;
int minx = 0, miny = 0;
for(int i = 0; i < (signed)tmp.size(); i++) {
minx = std::min(minx, tmp[i].x);
miny = std::min(miny, tmp[i].y);
}
int deltaX = 1 - minx, deltaY = 1 - miny;
for(int i = 0; i < (signed)tmp.size(); i++) {
int x = tmp[i].x + deltaX, y = tmp[i].y + deltaY;
clu[x][y] = rclu[x][y] = 1;
n = std::max(n, x), m = std::max(m, y);
}
for(int i = 1; i <= n; i++) std::reverse(rclu[i]+1, rclu[i]+1+m);
}
再看 hashClu, 这里我们需要把八个东西都哈希一遍。最后记得排序, hash1-4 就是四种不同的方向, Z 是正,F 是反。也不难写,是吧。
twt hashClu(int n, int m) {
twt an;
for(int i = 1; i <= 3; i++) { // 三哈希!
an.insert(i, hash1(Z, n, m, i)), an.insert(i, hash1(F, n, m, i));
an.insert(i, hash2(Z, n, m, i)), an.insert(i, hash2(F, n, m, i));
an.insert(i, hash3(Z, n, m, i)), an.insert(i, hash3(F, n, m, i));
an.insert(i, hash4(Z, n, m, i)), an.insert(i, hash4(F, n, m, i));
}
an.Sort();
return an;
}
hash 是要注意的,四种方向不是转换一个轴就可以的,赛场上我还因此而调试了一会儿,要根据实际的旋转情况定顺序,确保相似的图形遍历到每个元素的顺序都是一样的,处理行,我使用了乘十。
int hash1(int opt, int n, int m, int p) {
p = mods[p];
long long an = 0;
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++)
if(opt == Z) an = (an * 2ll + (long long) clu[i][j]) % (long long) p;
else an = (an * 2ll + (long long) rclu[i][j]) % (long long) p;
an = an * 10 % p;
}
return an;
}
int hash2(int opt, int n, int m, int p) {
p = mods[p];
long long an = 0;
for(int i = n; i >= 1; i--) {
for(int j = m; j >= 1; j--)
if(opt == Z) an = (an * 2ll + (long long) clu[i][j]) % (long long) p;
else an = (an * 2ll + (long long) rclu[i][j]) % (long long) p;
an = an * 10 % p;
}
return an;
}
int hash3(int opt, int n, int m, int p) {
p = mods[p];
long long an = 0;
for(int j = 1; j <= m; j++) {
for(int i = n; i >= 1; i--)
if(opt == Z) an = (an * 2ll + (long long) clu[i][j]) % (long long) p;
else an = (an * 2ll + (long long) rclu[i][j]) % (long long) p;
an = an * 10 % p;
}
return an;
}
int hash4(int opt, int n, int m, int p) {
p = mods[p];
long long an = 0;
for(int j = m; j >= 1; j--) {
for(int i = 1; i <= n; i++)
if(opt == Z) an = (an * 2ll + (long long) clu[i][j]) % (long long) p;
else an = (an * 2ll + (long long) rclu[i][j]) % (long long) p;
an = an * 10 % p;
}
return an;
}
然后是简单的查找和染色,没有什么好说的。
最后是一堆同样重要的定义。
const int N = 105, Z = 123, F = 321;
char map[N][N];
int clu[N][N], rclu[N][N], vis[N][N], n, m, totC, vis2[N][N];
int dx[9] = {0, 1, 1, 1, -1, -1, -1, 0, 0},
dy[9] = {0, -1, 0, 1, -1, 0, 1, 1, -1},
mods[4] = {0, 998244353, 1000000007, 1000000009};
struct point { int x, y; };
std::queue<point> que;
std::vector<point> tmp;
struct twt {
std::vector<int> wc[3];
twt() { wc[0].clear(), wc[1].clear(), wc[2].clear(); }
void insert(int p, int x) {
p--;
wc[p].push_back(x);
}
void Sort() {
std::sort(wc[0].begin(), wc[0].end());
std::sort(wc[1].begin(), wc[1].end());
std::sort(wc[2].begin(), wc[2].end());
}
bool operator == (twt b) const {
for(int i = 0; i < 3; i++)
if(wc[i].size() != b.wc[i].size()) return false;
for(int i = 0; i < 3; i++)
for(int j = 0; j < wc[i].size(); j++)
if(wc[i][j] != b.wc[i][j]) return false;
return true;
}
};
std::vector<twt> clusters;
就完成了。
赛场上 行的代码准确地实现了自己的思路,还是让人很舒服的,尽管还是少考虑了一点。
模块化的思路,化那么复杂的一个操作变为很好写的小操作,并在赛场上完成,体现了代码能力的增长和严密,还是让我很开心的。
T4
这似乎是一道原创题,很好的好题,代码极短。
赛场也模拟了较大的样例,但却想歪了,错失发现正解的机会。
给定一个由
M和F组成的序列,每一秒MF会交换成FM,问多少次后不能交换。
赛场上模拟了这样的一个数据。
MFFFFMMFFMMMFMFFF
大概是这样的(用 $0 $ 代替 M, 代替 F)
01111001100010111
10111010100101011
11011101001010101
11101110010101010
11110110101010100
11111011010101000
11111101101010000
11111110110100000
11111111011000000
11111111101000000
11111111110000000
然后画出 的运动路径(大概这个样)
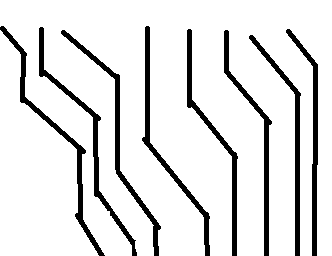
就发现相撞转折一直是单调递增的,而每个点最多被撞一次,所以用类似单调队列的方法找新的这一个撞到的。
这似乎是对的,但是仔细观察,我们有更简单的方法。
要求就是要把后面的 M 堆到后面的相应位置,所以至少要和 F 进行交换,主要是在多个 M 连在一起,这个就得等前面的移掉后再来,所以答案要加上 1, 如果至少要的都更多,那么肯定不会交上了,两个取 即可。
感觉这其实是巧妙的处理了前面的碰撞?
#include <cstdio>
#include <cstring>
#include <algorithm>
char st[1000005];
int cnt, ans;
int main() {
scanf("%s", st+1);
int n = strlen(st+1);
for(int i = n; i >= 1; i--)
if(st[i] == 'F') cnt++;
else if(cnt != 0) ans = std::max(ans+1, cnt);
printf("%d", ans);
}
明天 NOI Online 加油!
下次模拟赛加油!